几乎科技界的每个人都同意,对于我们可以用软件做什么以及我们可以用软件自动化做什么来说,生成式人工智能、大语言模型以及 ChatGPT 属于代际变化。关于大语言模型的其他问题并没有达成太多共识——事实上,我们仍在研究争论的焦点是什么——但每个人都同意会出现更多的自动化,以及全新类型的自动化。而自动化意味着岗位,以及人。
这种情况的进展速度也非常快:仅仅六个月后,ChatGPT 就拥有了(显然) 1 亿以上的用户,而来自Productiv的数据表明,它已经是排名前十的“影子 IT” app(编者按:指的是没有经过正式批准就被员工使用的app)。那么,这会夺走多少工作岗位,速度有多快,是否会有新的工作岗位来取代它们?
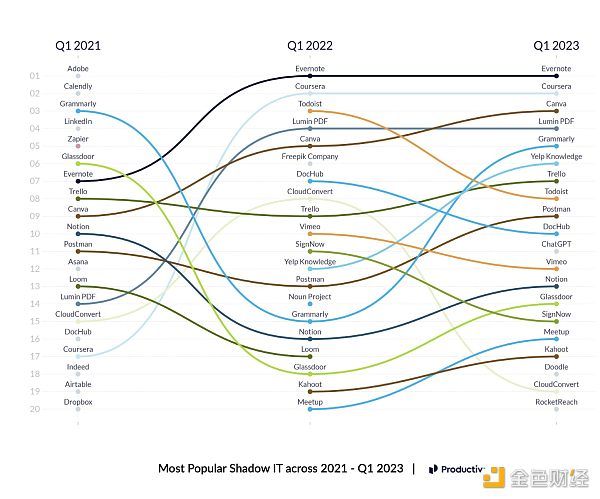
最近几年最热门的影子IT应用
首先我们应该记住的是,工作自动化的进程已经有 200 年了。每当我们经历一波自动化浪潮时,就会有一整个类别的工作会消失,但新的工作门类也会被创造出来。在这个过程当中会存在阵痛和错位,有时候新的工作岗位会分配给不同地方不同的人,但随着时间的推移,工作岗位总数不会下降,我们会变得更加繁荣富足。
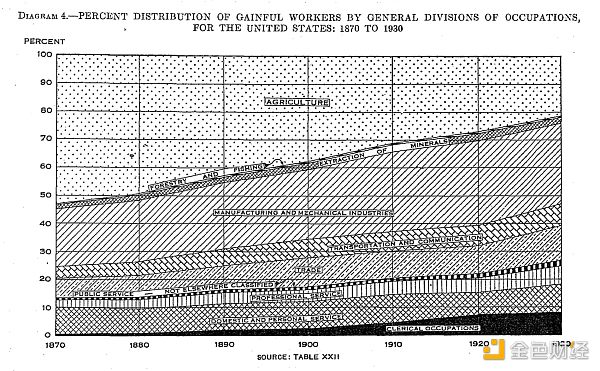
美国人口普查(按行业),1870年—1930年
当这种情况发生在你们这一代人身上时,人们自然而然地会担心这一次不会再有新的工作岗位出现。我们可以看到一些工作岗位正在消失,但我们无法预测新的工作岗位会是什么,而且通常它们还不存在。根据经验,我们知道(或应该知道),过去总会有新工作出现,而且这些工作也是不可预测的:1800 年的时候,没人会预测到 1900 年有一百万美国人从事“铁路”工作, 1900 年的时候,没人会预见到“视频后期制作”或“软件工程师”会成为一个工作类别。但仅仅因为过去一直都这样,就相信这种情况现在还会发生似乎还不够。你怎么知道这次会延续之前的情况呢?这次会不一样吗?
在这一点上,任何一位一年级的经济学学生都会告诉我们,这个问题这样子回答是犯了“劳动合成”(Lump of Labour)谬误。
劳动总量谬误是这样一种谬误,即认为社会中需要做的工作总量是固定的,如果机器承担了部分工作,那么留给人类的工作就会减少。但是,如果用机器制造一双鞋变得更便宜的话,则鞋子就会变得更便宜,于是就会有更多的人可以购买鞋子,他们就可以留出更多的钱去花在其他东西上,我们就会发现我们需要或者想要的新东西或新的工作。效率的提升并不局限在鞋子上:一般来说,它会通过经济向外扩散,创造新的繁荣和新的就业机会。因此,虽然我们不知道新的工作岗位会是什么,但我们知道这样一个模式,它不仅能说明总会有新的工作岗位出现,而且还能说明为什么这是这个过程中固有的现象。不用担心人工智能!
我认为,今天这个模式面临的最根本的挑战是这样一个说法:不对,过去 200 年的自动化的实质是我们一直在提高人类能力的规模。

“伏尔加河上的驳船搬运工”,伊利亚·列宾,1870-73。 (注意右侧地平线上出现了冒烟的蒸汽船。)
作为人类,我们是从做苦力的野兽开始,然后向上发展的:我们先是自动化了自己的腿,然后是手臂,然后是手指,现在是大脑。我们一开始从事的是农场工作,然后是蓝领工作,再到白领工作,现在我们把白领工作也自动化了,已经没有什么可以自动化了。工厂被呼叫中心取代,但如果我们连呼叫中心也自动化了,那人类还剩下什么可以做的?
关于这个问题,我认为了解另一段经济和科技史会有所帮助:杰文斯悖论(Jevons Paradox)。
19世纪的英国海军还要靠烧煤来让船跑起来。那时候英国拥有大量煤炭(那时候的英国就是蒸汽时代的沙特阿拉伯),但人们担心煤炭耗尽后该怎么办。呃,工程师们说:别担心,因为蒸汽机的效率会越来越高,所以我们使用的煤炭会越来越少。但杰文斯说,不:如果我们让蒸汽机变得更高效,那么它们的运行成本就会更低,我们就会使用更多的蒸汽机,并将这些蒸汽机用于新的、不同的事物上,所以我们会使用更多的煤炭。创新可以与价格弹性建立关联。
150 年来,我们一直将杰文斯悖论应用在白领工作上。

替代手工抄写的打字机

替代人工簿记的加法机
还不存在的未来工作很难想象,但过去的部分工作已经被自动化所取代也很难想象。 在果戈里的笔下,1830 年代被剥削的职员整个职业生涯都消耗在复印文件上,一次一份,全靠手工。他们就是人类复印机。到了 1880 年代,打字机已经可以以每分钟两倍字数的速度打印出清晰易读的文本,而复写机也能提供六份免费副本了。打字机意味着一名职员的产出量可以提高 10 倍以上。几十年后,像 Burroughs 这样的公司制造的加法机对簿记和会计也做了同样的事情:你再也不用拿起笔进行累加了,而是用机器完成,时间只需要过去的20%,而且还不会出错。
这对文员的就业有何影响?结果社会雇佣了更多的文员。自动化加上杰文斯悖论意味着创造出更多的就业机会。
如果配置了一台机器的文员可以完成过去 10 名文员所做的工作,那么你的文员可能会减少,但你也可能会用这些人做更多的事情。杰文斯告诉我们,如果做某事变得更便宜、更高效的话,你可能会做更多这样的事情——你可能会进行更多的分析,或管理更多的库存。你可能会建立一个不一样的、更高效的企业,这之所以成为可能,是因为你可以用打字机和加法机实现业务管理的自动化。
历史在不断重复着这个过程。这是 1960 年《公寓》中杰克·莱蒙 (Jack Lemmon) 饰演的 CC Baxter,他使用的是 Friden 的机电加法机,五十年前,加法机才刚刚出现,令人兴奋。

机电加法机
这个镜头里面的每一个人都是电子表格中的一个单元格,整栋建筑物则是一个电子表格。每周一次地,楼顶会有人按下 F9,然后他们就开始会重新计算。但他们已经有了计算机,并且到了 1965 年或 1970 年地时候,他们购买了一台大型机,并废弃了所有的加法机。那白领岗位崩溃了吗?或者,就像 IBM 所宣传的那样,计算机是不是给你额外增加了 150 名工程师? 25 年后,PC 革命以及小盒子内的会计部门对会计又产生了什么影响?

IBM称拥有一台大型机相当于多了150名工程师

桌面版会计系统的广告:一个小盒子取代一个会计部门
Dan Bricklin 在 1979 年发明了计算机电子表格:在那之前,“电子表格”都是纸质的(你仍然可以在亚马逊上买到)。关于电子表格地早期使用,他讲述了一些有趣地故事:“人们会这么告诉我,‘所有这些工作都是我做的,同事们认为我很棒。但我其实很懒,因为做完那些事情我只花了一个小时,然后剩下的时间我都是在休息。别人认为我是神童,但我只是使用了这个工具罢了。”
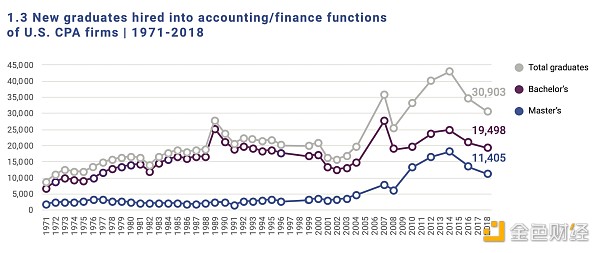
EXCEL、PC出现后,会计岗位不降反升
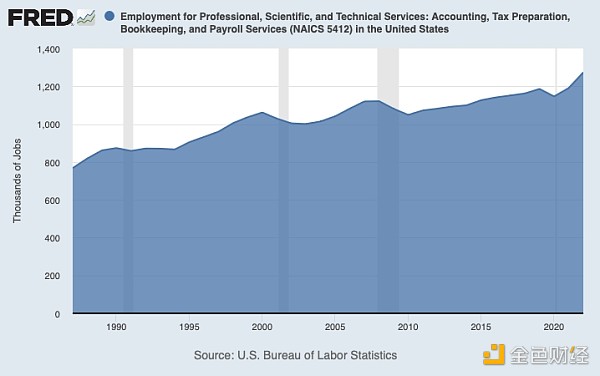
美国1990-2020年间会计、簿记、工资服务、纳税服务相关岗位情况
那么,Excel和PC对会计岗位有何影响呢?会计的岗位增加了。
40 年后,电子表格是不是意味着你可以早点休息了?其实不然。
年轻人可能不相信这一点,但在电子表格出现之前,投资银行家的工作时间确实很长。多亏有了 Excel,高盛的员工才能完成所有工作并在周五下午 3 点离开办公室。现在,大语言模型意味着他们每周只需工作一天!
新技术通常会让做某件事情变得更便宜、更容易,但这可能意味着你可以用更少的人做同样的事情,或者你可能也可以用同样的人做更多的事情。它还往往意味着你改变了要做的事情。一开始,我们让新工具适应旧的工作方式,但随着时间的推移,我们开始改变工作方式来适应这个工具。当 CC Baxter 所在的公司购买大型机时,他们先是将现有的工作方式自动化,但随着时间的推移,新的业务运营方式成为可能。
因此,所有这一切都表明,默认情况下,我们应该期望大语言模型能够像 SAP、Excel、大型机或打字机一样颠覆、取代、创造、加速和增加就业机会。这只是有了更多的自动化。机器可以让一个人完成十倍的工作,但你还是需要这个人。
对于这种看法,我认为有两个反驳论据。
第一条,是,也许这确实与我们从互联网、个人电脑或PC上看到的变化更为相似,或许着不会对净就业产生长期影响,但这一次发生的速度会更快,因此带来的阵痛会更大,调整起来也会更加困难。
LLM 与 ChatGPT 的发展速度肯定比 iPhone、互联网,甚至个人电脑要快得多。 Apple II 的上市时间是 1977 年,IBM PC 上市时间为 1981 年,Mac 上市时间为 1984 年,但直到 20 世纪 90 年代初,PC 的使用量才达到 1 亿台:但推出仅仅六个月后, ChatGPT 用户数就达到了 1 亿。你不需要等电信公司建立宽带网络,或者等消费者购买新设备,生成式人工智能,是建立在过去十年建立起来的一整个技术栈的基础之上的:云计算、分布式计算以及众多机器学习技术栈。对于用户来说,它只是一个网站。
如果你再思考一下来自Productiv和 Okta(了用不同方法)的这些图表的意味时,你的预期可能会有所不同。他们这两家公司报告称,其典型客户现在拥有数百种不同的软件应用,而企业客户拥有的软件数量则有近 500 种。
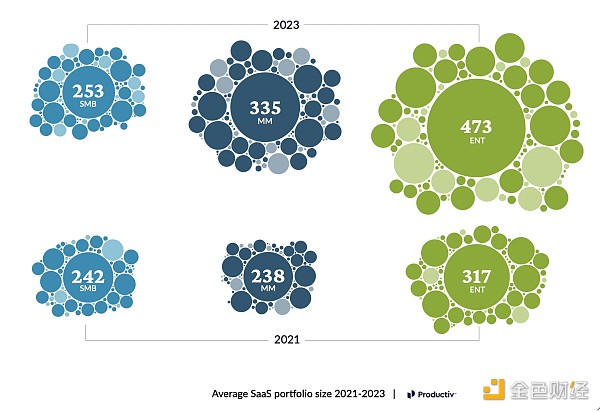
中小企业、大企业拥有的SaaS应用数量不断增长
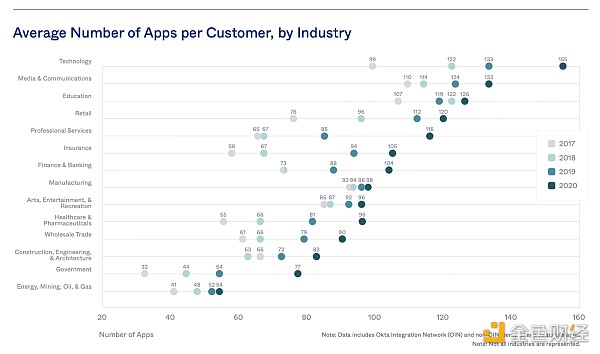
不同行业的平均app数量也是增长趋势(每客户)
可是,企业对云计算的采用率仍仅占工作流的四分之一。
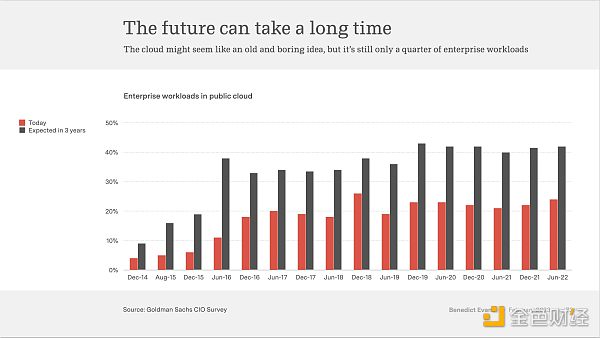
云化的道路还很长
这对于工作场所的生成式人工智能意味着什么?不管你认为会发生什么事情,其所需要的时间都会是数以年计,而不是以周计。
人们用来完成手头工作的工具,以及某些现在可能会有一层新的自动化分担的任务,是非常复杂且非常专业的,里面可能集成了大量的工作和机构知识。很多人都在尝试 ChatGPT,看看它能做什么。也许你就是其中之一。但这并不意味着 ChatGPT 已经取代了他们现有的工作流,替换或自动化掉这些工具和任务中的任何一个都不是小事。
变革性技术一次令人惊叹的演示,与一家大型复杂公司持有的,别人的业务可以使用的东西之间存在巨大差异。你登门拜访律师事务所时,很少只是为了兜售一个 GCP (谷歌云平台)的翻译或情绪分析的 API 密钥:你需要把它包装进控制、安全、版本控制、管理、客户权限以及只有法律软件公司才知道的一大堆其他内容里面(在过去十年的时间里,很多机器学习公司已经认识到了这一点)。公司一般都没法买“技术”。 Everlaw不卖翻译,People.ai 也不卖情感分析——他们卖工具和产品,而人工智能通常只是其中的一部分。我不觉得文本提示、“开始”按钮、黑箱、通用文本生成引擎能成为产品,产品需要时间。
与此同时,购买管理大型复杂事物的工具也需要时间,哪怕这种工具已经开发出来并找到了产品市场匹配。要想做企业软件初创企业,面临的最基本挑战之一是初创公司的融资周期为18 个月,而许多企业的决策周期就要 18 个月。 SaaS本身加速了这格周期,因为你不需要进入企业数据中心的部署计划,但你还是得购买、集成和培训,而对于拥有数百万客户以及数万或数十万员工的公司来说,不要一下子就做出改变是有充分理由的。到达未来需要一段时间,硅谷以外的世界很复杂。
第二个反驳论据是,ChatGPT 和 LLM 范式转变的一部分是抽象层的转变:这看起来像是一种更通用的技术。确实,这就是它令人兴奋的原因。他们告诉我们,它可以回答任何问题。因此,你可以看看那张图里面的473 个企业 SaaS 应用,然后说 ChatGPT 会颠覆这一切,然后将许多垂直应用折叠到一个提示框之中。这意味着它会发展得更快,并且自动化程度更高。
我认为这是误解了这个问题。如果律师事务所的合伙人想要一份文件的初稿,他们对参数调整的要求会与处理索赔的保险公司销售人员完全不同,他们可能会使用不同的训练集,当然还有一堆不同的工具。 Excel 也是“通用用途”工具,SQL 亦然,但是有多少种不同类型的“数据库”呢?这就是我认为大语言模型的未来会从提示框转向 GUI 和按钮的原因之一 —— 我认为,“提示工程”与“自然语言”这两个东西是相互矛盾的。但不管是哪一种,就算你可以在一个庞大的基础模型之上把一切作为一层薄薄的封装来运行(而且对于这一点大家还没有达成一致或明确),这些封装也是需要时间的。
事实上,虽然有人可能会认为大语言模型会在一个轴向上将许多应用纳入其中,但我认为,随着初创公司从 Word、Salesforce 和 SAP 剥离出更多用例,它们同样有可能在其他轴向上掀起一波全新的解绑浪潮,同时,通过解决在大语言模型让你具备解决能力之前没人意识到的问题来建立一大堆更大的公司。毕竟,这个进程解释了为什么大公司如今会拥有 400 个 SaaS 应用。
当然,更根本的问题是错误率。 ChatGPT 是“任何问题”都可以回答,但答案可能是错的。大家称之为幻觉、编造事实、撒谎或胡说八道——这就是“过于自信的大学生”问题。但我认为这样的思维框架没什么帮助:我认为理解这一点的最好办法是,当你在提示框输入某些内容时,其实根本就没有要求它回答问题。相反,你想问的是“人们可能会对这样的问题给出什么样的答案?”你要求它匹配一个模式。
因此,如果我让 ChatGPT4 写一篇我自己的传记,然后再问它,它会给出不同的答案。它会说我上过剑桥、牛津或伦敦经济学院(LSE);我的第一份工作是做股票研究、咨询或财经新闻。这些总是对的模式:正确的大学类型,正确的工作类型(它从来没说我上过麻省理工学院,然后第一份工作是餐饮管理)。对于“像我这样的人可能拿到的是什么类型的学位,从事什么样的工作?”这个问题,它给出了 100% 正确的答案。对于这个问题,它不是在进行数据库查询:而是在创建一个模式。
这张图是我用MidJourney生成的,换你来也能得出类似的内容。提示词是“戛纳国际创意节,海滩边,广告从业人员在研讨会台上讨论创意的照片。”

图片与模式几乎完美匹配——看起来很像戛纳的海滩,这些人的服装很像广告人,连发型也很合适。但它什么都不知道,所以它不知道人从来没有三条腿,只知道这不太可能。这不是“撒谎”或“编造”——它是在匹配一个模式,只不过不够完美。
不管你怎么称呼它,如果你不理解这一点,你就会遇到麻烦,就像这位不幸的律师所经历的情况那样,他不明白,当他要求提供判例时,他其实是在要求看起来像判例的东西。他适时地得到了看似是判例的东西,但事实并非如此。它不是数据库。
如果你确实明白了这一点,那你就得问一个问题,LLM 有什么用处?把本科生或实习生(这些人可以重复你可能需要检查的模式)自动化有什么用处?上一波机器学习给你带来了无数的实习生,这些实习生是可以替你阅读任何东西,但你必须检查,现在我们有了无数可以为你写任何东西的实习生,但你也必须检查。那么这些数量无限的实习生有什么用呢?问问Dan Bricklin——我们又回到了杰文斯悖论。
显然,话题就讲到了通用人工智能(AGI)。对于我刚才所说的一切,真正根本的反驳是提问,如果我们有一个错误率为零、没有幻觉,并且确实可以做人可以做的任何事情的系统的话,情况会怎么样?如果我们有了这个东西,那你可能不需要一名产出相当于十名普通会计,会用EXCEL的会计了:你可能只需要那台机器就行了。那么这一次的话,情况也许真的会有所不同。以前的自动化浪潮意味着一个人可以做更多的事情,但现在你已经不需要这个人了。
不过,就像许多 AGI 问题一样,如果你不小心的话,这可能会变成一个死循环。 “如果我们有一台可以做人能做的任何事情的机器,又没有任何这些限制的话,那么它会做人能做的任何事情,并且没有这些限制吗?”
嗯,确实,如果是这样的话,我们可能会遭遇的问题就比中产阶级就业问题还要大,但我们距离这个已经很接近了吗?也许就算你用了几周的时间仔细观看计算机科学家争论这个问题的三个小时 YouTube 视频,最后得出的结论也是他们其实也不知道。你可能还会认为,这个神奇的软件将改变一切,并超越真实的人、真实的公司以及实体经济的各自复杂性,并且现在可以在几周而不是几年之内部署,这听起来像是经典的技术解决主义,但从乌托邦变成了反乌托邦。
不过,作为一名分析师,我更倾向于认可休谟的经验主义而不是笛卡尔的哲学——我只能分析我们所能知道的东西。我们还没有通用人工智能,在没有通用人工智能的情况下,我们就只会有另一波的自动化浪潮,而且我们似乎没有任何先验的理由来解释为什么这次就一定会比之前的其他所有浪潮多多少少要更痛苦些。



