原文作者:Bryan, IOSG Ventures
过去的 2022 年关于 rollup 主要的讨论焦点似乎都集中在 ZkEVM,但是别忘记 ZkVM 也是另一种扩容手段。虽然 ZkEVM 并不是本文的重点,但是值得回味一下 ZkVM 与 ZkEVM 之间几个维度的不同之处:
兼容性:虽然都是扩容,但是侧重点并不同,ZkEVM 的侧重点在于直接实现与现有 EVM 的兼容,而 ZkVM 的定位在于实现完全的扩容,也就是将 dapp 的逻辑以及性能提升到最优,兼容性并不是首要的。底层搭好了,EVM 兼容也可以实现。
性能:两者都有比较可以预见的性能方面的瓶颈,ZkEVM 主要瓶颈在于兼容 EVM 这样一个并不适合封装在 ZK 证明系统时产生的多余成本。ZkVM 的瓶颈在于因为引入了指令集 ISA,导致最终输出的约束更复杂。
开发者体验:Type II ZkEVM ( 如 Scroll, Taiko) 主打的是对于 EVM Bytecode 的兼容,换句话说就是 Bytecode 级别及其以上的 EVM 代码都可以通过 ZkEVM 产生对应的零知识证明。对于 ZkVM 来说,有两个方向,一个方向是做自己的 DSL( 如 Cairo), 另一个则是目标兼容现有的比较成熟的语言如 C++/Rust(如 Risc 0)。未来我们预计原生的 solidity 以太坊开发者会可以无成本迁移至 ZkEVM,而更新更强大的应用则会跑在 ZkVM 上。

很多人应该还记得这张图,CairoVM 事不关己游离于 ZkEVM 派系斗争的本质原因是设计思想的不同
在讨论 ZkVM 之前,我们首先思考的是如何在区块链中实现 ZK 证明系统。大致上,有两种方法实现电路 - 基于电路的系统 (circuit based) 以及基于虚拟机的系统 (vm-based)。
首先,基于电路的系统的功能是将程序 (program) 直接转化为约束条件 (constraints) 并送入证明系统 (proving system);基于虚拟机的系统通过指令集 (ISA) 执行程序,在此过程中产生执行轨迹 (execution trace)。这个执行轨迹之后会被映射成约束条件,然后被送入证明系统。
对于一个基于电路的系统,程序的计算由执行程序的每台机器 (machine) 进行约束。而对于基于虚拟机的系统,ISA 被嵌入到电路产生器 (circuit generator) 中,并产生程序的约束 (constraints),同时电路产生器有指令集、运行周期、内存等等限制。虚拟机提供了通用性,即任何机器都可以运行一个程序,只要该程序的运行条件在上述限制范围内。
在虚拟机中一个 zkp 程序大概经历如下的流程:

图片来源: Bryan, IOSG Ventures
优缺点:
从开发者 (developer) 的角度来看,在基于电路的系统中开发通常需要对每个约束条件的成本有深入的了解。然而,对于编写虚拟机程序来说,电路是静态的,开发者需要更关心的是指令 (instructions)。
从验证者 (verifier) 的角度来看,假设使用相同的纯 SNARK 作为后端,基于电路的系统和虚拟机在电路的通用性方面有很大的不同。电路系统对每个程序产生不同的电路,而虚拟机对不同程序产生相同的电路。这意味着,在一个 rollup 中,电路系统需要在 L1 上部署多个验证合约 (verifier contract)。
从应用 (application) 的角度来看,虚拟机通过将内存模型 (memory) 嵌入到设计中,使应用程序的逻辑更加复杂,而使用电路系统的目的是为了提高程序的性能。
从系统复杂性 (complexity) 的角度来看,虚拟机将更多的复杂性纳入系统,如内存模型、主机 (host) 和客户 (guest) 之间的通信等,相比之下电路系统更简洁。
以下是目前 L1/L2 中基于电路和基于虚拟机的不同的项目预览:
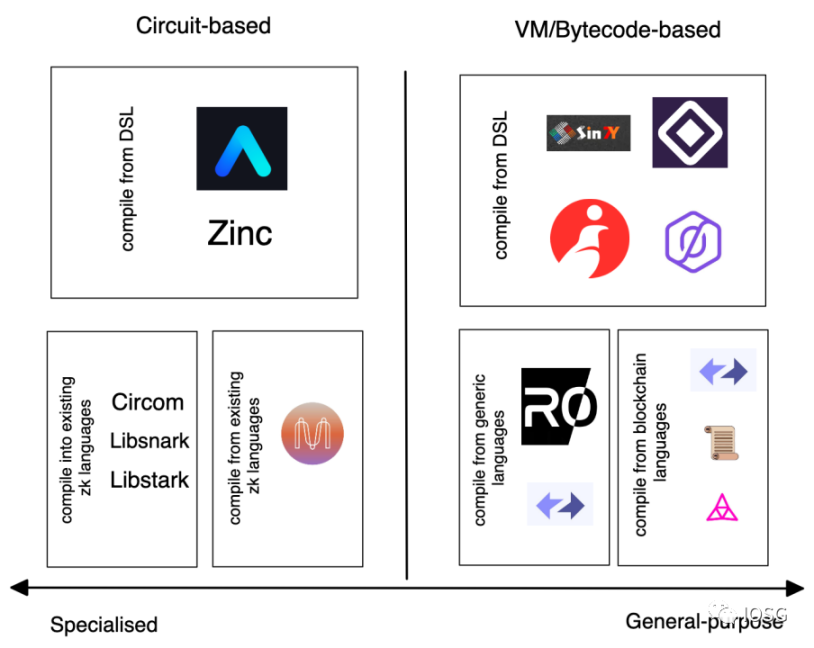
图片来源: Bryan, IOSG Ventures
虚拟机的设计原则
在虚拟机中,有两个关键的设计原则。首先,确保程序被正确执行。换句话说,输出 (output)(即约束条件 constraint)与输入 (input)(即程序 program)应当正确匹配。一般这是通过 ISA 指令集完成的。其次,确保编译器 (compiler) 在从高级语言转换为适当的约束格式时能正确工作。
1. ISA 指令集
规定了电路产生器的工作方式。它的主要责任是将指令 (instructions) 正确地映射到约束条件 (constraint) 中,这些约束条件随后被送入证明系统 (proving system)。zk 系统使用的都是 RISC( 精简指令集 )。有两种 ISA 的选择:
第一种是自建一个自定义的 ISA(custom ISA),这在 Cairo 的设计中可以看到。一般来说,有如下四种类型的约束逻辑。

自定义 ISA 的基本设计重点是确保约束条件尽可能少,从而使程序的执行和验证都能快速运行。
第二种是利用现有的 ISA(existing ISA),这在 Risc 0 的设计中被采用。除了以简洁的执行时间为目标外,现有的 ISA(如 Risc-V)还提供了额外的好处,如对前端语言 (front-end language) 和后端硬件 (backend hardware) 友好。一个(有待解决的可能)问题是,现有的 ISA 会不会在验证时间上有所落后(因为验证时间并不是 Risc-V 的主要设计追求。
2. 编译器 (Compiler)
笼统地来说,编译器会逐步将编程语言翻译成机器代码。在 ZK 的环境下,它指的是使用 C、C++、Rust 等高级语言编译成约束系统(R 1 CS、QAP、AIR 等.)的低级代码表示。有两种方法,
设计一个基于现有 zk 电路表示 (existing circuit representations) 的编译器 -- 比如说在 ZK 中,电路表现形式从 Bellman 这样的可以直接调用的库 (library) 和 Circom 这样的低级语言开始。为了聚合不同的表现形式,Zokrates 这样的编译器(身也是一个 DSL)旨在提供一个抽象层,可以编译成任意的更低级表现形式。
基于(现有的)编译器基础设施 (compiler infrastructure) 来构建。基本逻辑是利用一个针对多个前端和后端的中间表现形式 (intermediate representation)。
Risc 0 的编译器是基于 multi-level intermediate representation(MLIR),可以生成多个 IR(类似于 LLVM)。不同的 IR 给开发者带来了灵活性,因为不同的 IR 有各自的设计重点,例如其中有一些的优化是专门针对硬件,所以开发者可以根据自己的意愿进行选择。类似的想法在使用 GCC 的 vnTinyRAM 和 TinyRAM 中也可以看到。ZkSync 也是另一个利用编译器基础设施的例子。
此外,你还可以看到一些针对 zk 的编译器基础设施,如 CirC,它也借用了 LLVM 的一些设计理念。
除了上述两个最关键的设计步骤外,还有一些其他的考虑因素:
1.系统的安全性 (security) 和验证的成本 (verifier cost) 之间的权衡
系统使用的比特数越高(即安全性越高),意味着验证的成本越高。安全性反映在密钥生成器(比如在 SNARK 中代表椭圆曲线)。
2.与前端和后端的兼容性 (compatibility)
兼容性取决于为电路的中间表示 (intermediate representation) 的有效性。IR 需要在正确性(程序的输出是否与输入相匹配 + 输出是否符合证明系统)和灵活性(支持多种前端和后端)之间取得了平衡。如果 IR 最初是为解决像 R 1 CS 这样的低度 (low-degree) 约束系统而设计的,那么与其他更高级别 (high-degree) 的约束系统如 AIR 的兼容就很难。
3.为提高效率需要手工制作 (hand-crafted) 电路
使用通用模型 (general purpose) 的缺点是,对于一些不需要复杂指令的简单操作,其效率较低。
简述一下先前的一些理论,
Pinocchio 协议之前: 实现了可验证的计算,但验证时间非常慢
Pinocchio 协议: 在可验证性和验证成功率方面提供了理论上的可行性(即验证的时间比执行程序的时间短),是基于电路的系统
TinyRAM 协议: 相对于 Pinocchio 协议,TinyRAM 更像一个虚拟机,引入了 ISA,因此摆脱了一些限制,如内存访问 (RAM)、控制流 (conttrol flow) 等
vnTinyRAM 协议: 使得密钥生成 (key generation) 并不取决每个程序,提供了额外的通用性。扩展电路产生器,即能够处理更大的程序。
上述模型都以 SNARK 作为其后端证明系统,但是特别是在处理虚拟机时,STARK 和 Plonk 似乎是一个更合适的后端,从根本上说是由于其约束系统更适合于实现 cpu 一样的逻辑。
接下来,本文会介绍三个基于 STARK 的虚拟机 - Risc 0, MidenVM, CairoVM。简而言之,除了都以 STARK 作为证明系统外,它们各自有一些不同:
Risc 0 利用 Risc-V 来实现指令集的简洁性。R 0 在 MLIR 进行编译,这是 LLVM-IR 的一个变种,旨在支持多种现有的通用编程语言,如 Rust、C++。Risc-V 还有一些额外的好处,比如对于硬件较为友好。
Miden 的目标是与以太坊虚拟机(EVM)兼容,本质上是 EVM 的 rollup。Miden 现在有自己的编程语言,但也致力于在未来支持 Move。
Cairo VM 是由 Starkware 开发的。这三个系统所使用的 STARK 证明系统是由 Eli Ben-Sasson 发明的,目前 Starkware 的总裁。
让我们更深入地了解它们的区别:
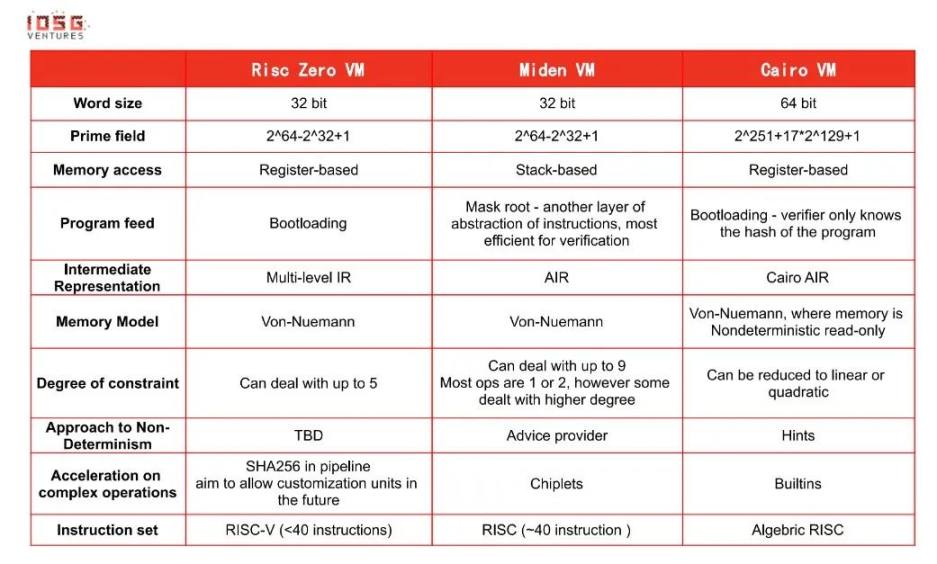
* 如何读懂上面的表格?一些注解...
Word size(字长) - 由于这些虚拟机所基于的约束系统是 AIR,其功能与 CPU 架构类似。所以选择 CPU 字长(32/64 位)比较合适。
Memory access(内存读取)- Risc 0 使用寄存器 (register) 的原因主要是 Risc-V 指令集是基于寄存器的。Miden 主要使用堆栈 (stack) 来存储数据,因为 AIR 的功能与堆栈类似。CairoVM 没有使用通用寄存器 (general-purpose register),因为 Cairo 模型中的内存访问 (main memory) 成本较低。
Program feed(程序执行)- 不同方法是有取舍的。例如,对于 mast root 方法来说,它需要在处理指令时进行解码,因此在执行步骤较多的程序中下证明者的成本较高
Bootloading 方法试图在保持隐私的同时在证明者成本和验证者的成本之间取得平衡。
Non-determinism(非确定性)- 非确定性是 NP-complete 问题的一个重要属性。利用非确定性有助于快速验证过去的执行。反过来说,它增加了更多的约束条件,因此在验证方面会有一些妥协。
Acceleration on complex operations(复杂运算的加速)- 有些计算在 CPU 上运行很慢。例如,位操作,如 XOR 和 AND,哈希程序 (hash program),如 ECDSA,还有范围检查 (range-check)......大多是区块链 / 加密技术的原生但不是 CPU 原生的运算(除了位操作)。直接通过 DSL 来实现这些运算会很容易导致证明的周期 (cycle) 耗尽。
Permutation/multiset ( 排列 / 多列组合 ) - 在大多数 zkVM 中大量使用,有两个目的 --1.通过减少存储完整的执行轨迹 (execution trace) 来降低验证者的成本 2.证明验证者知道完整的执行轨迹
文章最后笔者想谈谈 Risc 0 目前的发展以及其让我兴奋的原因。
R 0 目前的发展:
a.自研的「Zirgen」的编译器基础设施正在开发中。将 Zirgen 与一些现有的 zk 专用编译器的性能进行比较会很有趣。
b.一些很有意思的的创新,如 field extension,可以实现更坚实的安全参数以及在更大的整数上进行操作。
c.见证了在 ZK 硬件和 ZK 软件公司之间的整合中看到的挑战,Risc 0 使用了一个硬件抽象层,以便在硬件方面进行更好的开发。
d.Still a work-in-progress! 还在开发中!
支持手工制作的电路 (hand-crafted circuits),支持多种哈希算法。目前,专用的 SHA 256 电路已实现,然而还不能满足所有的需求。笔者相信具体选择优化哪类电路取决于 Risc 0 所提供的用例 (use case)。SHA 256 是一个非常好的起点。另一方面,ZKVM 的定位给人以灵活性,例如,只要他们不想,就不必去管 Keccak :)
递归 (recursion):这是一个很大的话题,笔者倾向于不在该报告进行深入研究。需要知道的是,随着 Risc 0 倾向于支持更复杂的用例 / 程序,更迫切地需要递归。为了进一步支持递归,他们目前正在研究一个硬件端的 GPU 加速方案。
处理非确定性 (non-determinism):这是 ZKVM 必须处理的一个属性,而传统的虚拟机是没有这个问题的。非确定性可以帮助虚拟机执行得更快。MLIR 相对更擅长处理传统虚拟机方面的问题,而 Risc 0 如何将非确定性嵌入到 ZKVM 系统设计中值得期待。
WHAT EXCITES ME:
a.简单且可验证!
在分布式系统中,PoW 需要高水平的冗余,因为人们不信任他人,因此需要重复执行相同的计算来达成共识。而通过利用零知识证明,状态的实现应该和同意 1+ 1 = 2 一样容易。
b.更多更实际的用例:
除了最直接的扩容外,更多有意思的用例将变得可行,比如零知识机器学习、数据分析等。相比于 Cairo 这样的特定的 ZK 语言,Rust/C++ 的功能更普适且更强大,更多 web2 的用例跑在 Risc 0 VM 上。
c.更具包容性 / 成熟的开发者社区:
对 STARK 和区块链感兴趣的开发者不必再重新学习 DSL,使用 Rust/C++ 即可。



